Digital Traces via Data Donations
Workshop DGPuK RezFo 2026
Session 3️⃣: Data Donation Studies (Researcher Perspective)
👉 Part of the SPP DFG Project Integrating Data Donations in Survey Infrastructure

Data Donation: Methodological Decisions
Data Donation: Methodological Decisions

For a summary: shoutout to this primer

Agenda
Research design & tool set-up
Data cleaning & augmentation, including
📢 Task 4: Classify search terms
Modelling
📢 Task 5: Example Analysis of YouTube Watch history

Image by Hope House Press via Unsplash
1) Research design & tool set-up

Source: Image by Markus Winkler via Unsplash
Step I: Research design & tool set-up
Step I: Research design & tool set-up
Step I.I Which questions do I want to answer?

Step I.I Which questions do I want to answer?

Step I: Research design & tool set-up
Step I.II: Which data donation tool do I use? 🖥️
Choose a tool, e.g., …
- Next (Boeschoten et al., 2023) (different measurements, different platforms)
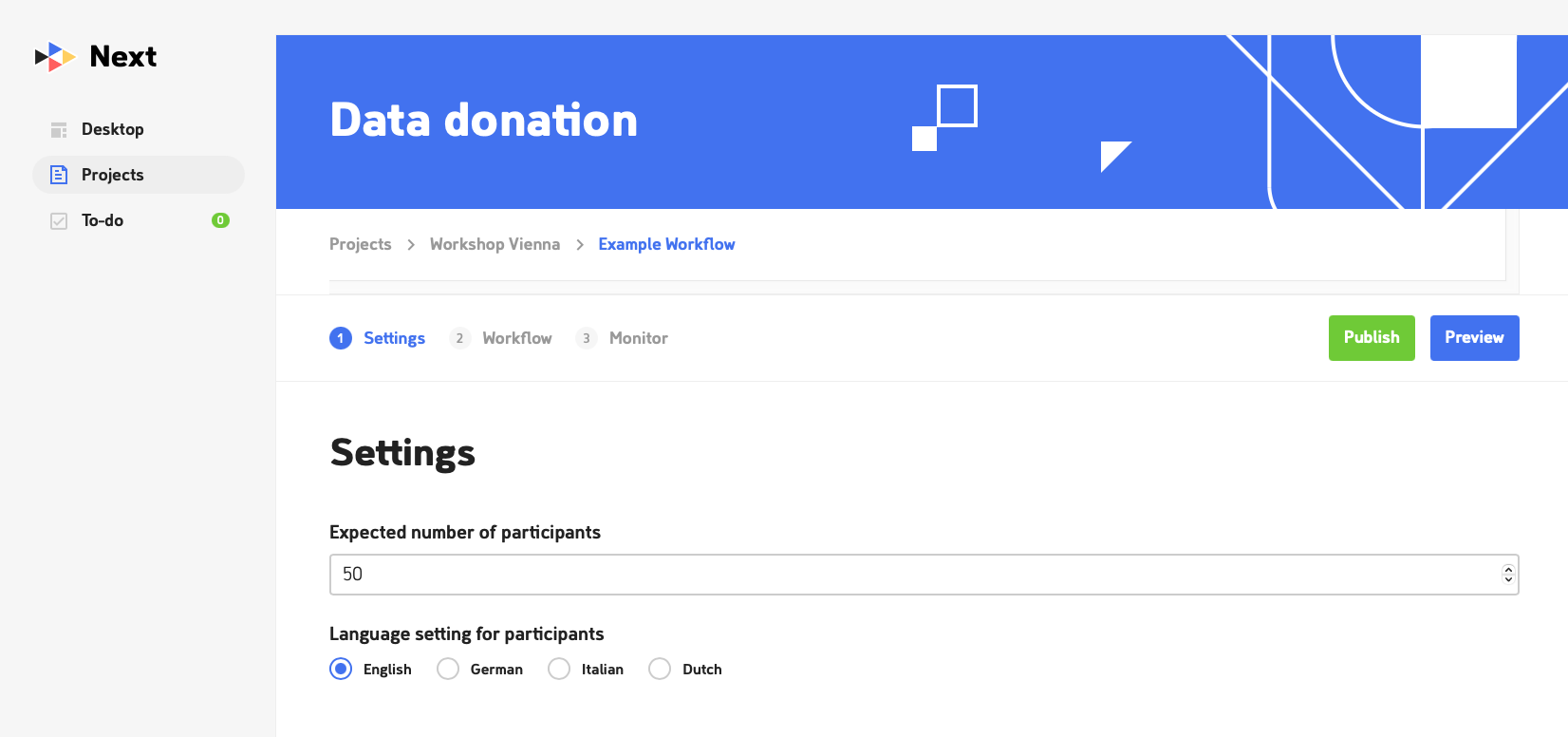
Step I.II: Which variables do I extract? 🔎
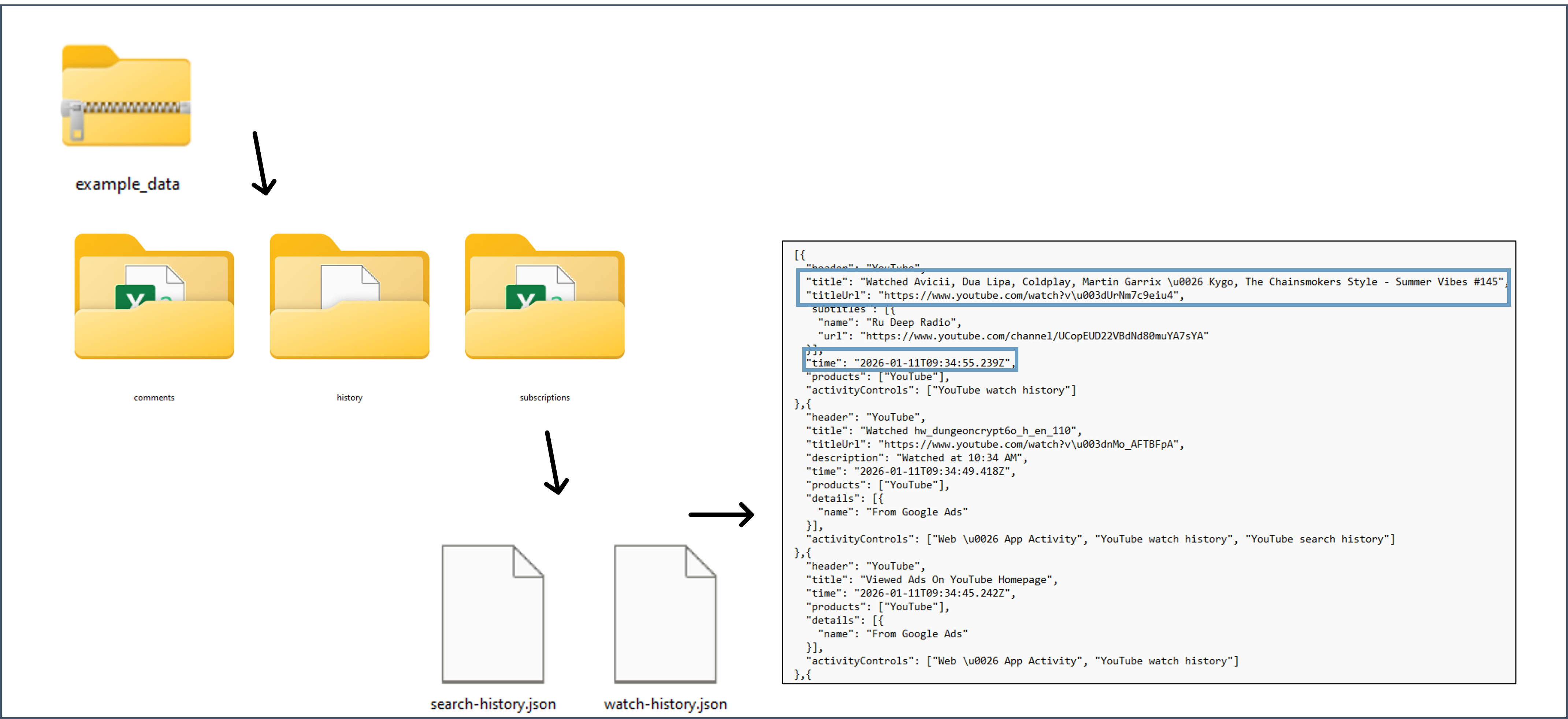
Step I.II: Which variables do I extract? 🔎
You can find the following Python code for data extraction here:
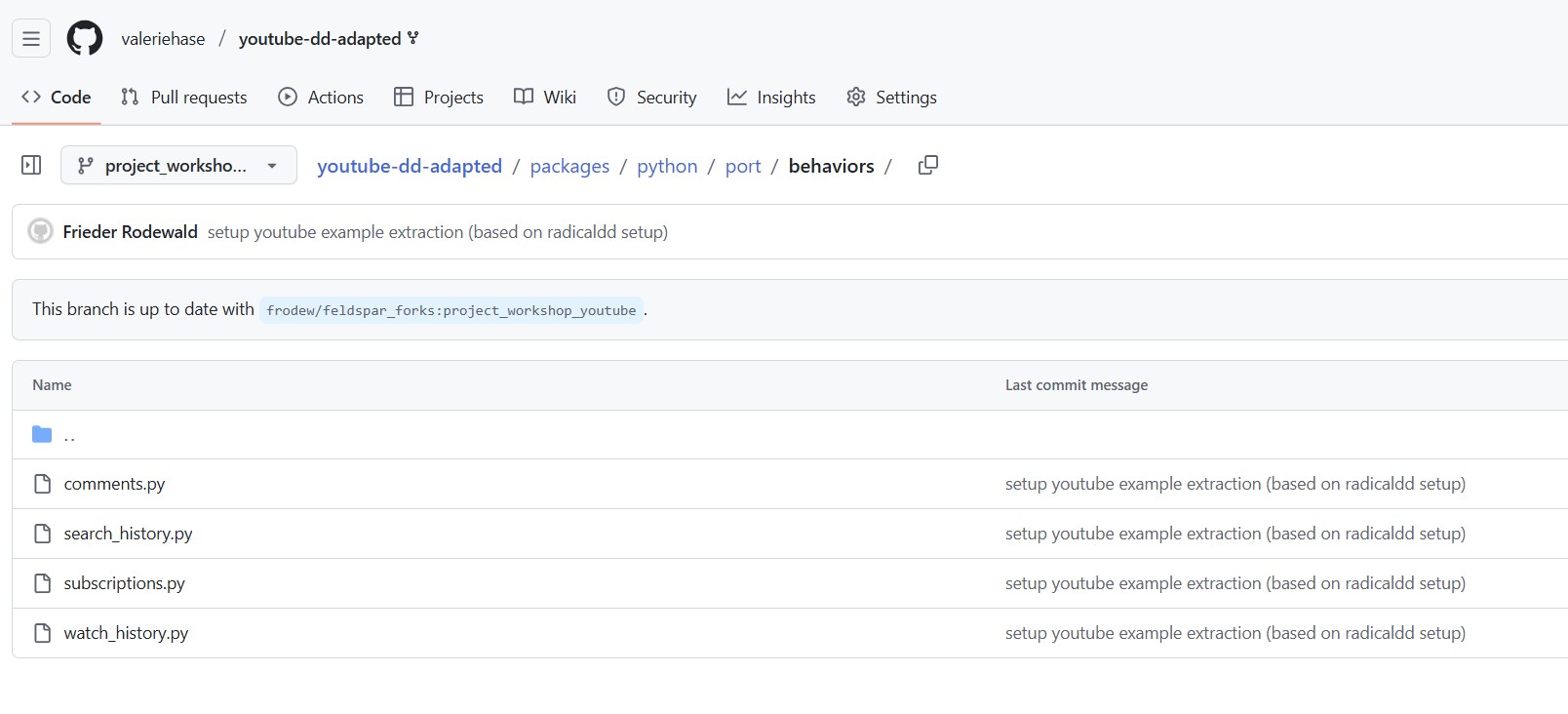
Step I.II: Which variables do I extract? 🔎
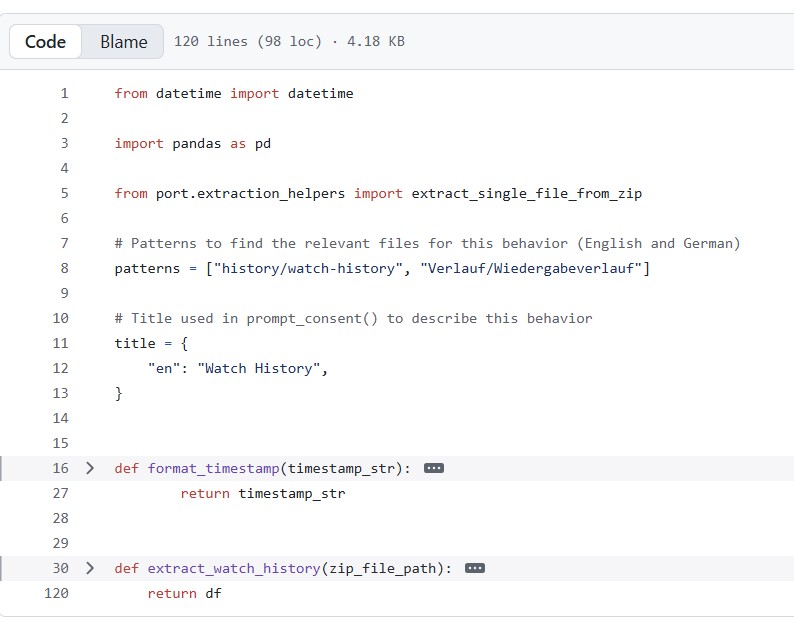
Step I.II: How do I anonymize data? 🙈
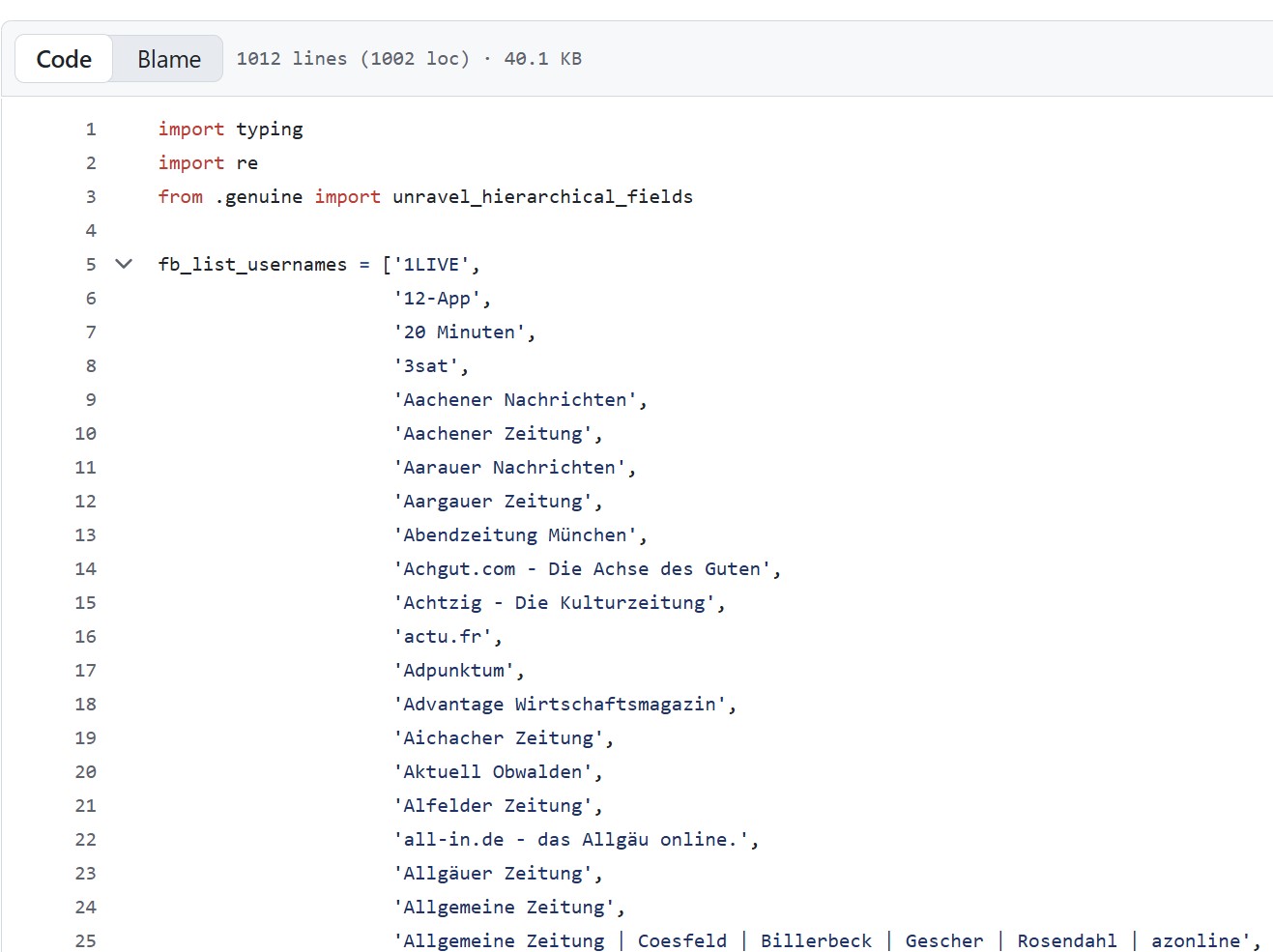
Figure. Exampe whitelist
Step I.II: How do I anonymize data? 🙈
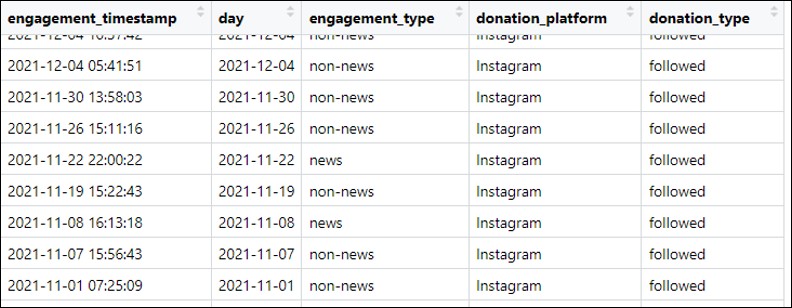
Figure. Example anonymized data
⚠️ Anonymized does not mean anonymous!

Figure. Next setup
Figure. Next setup
Figure. Next setup
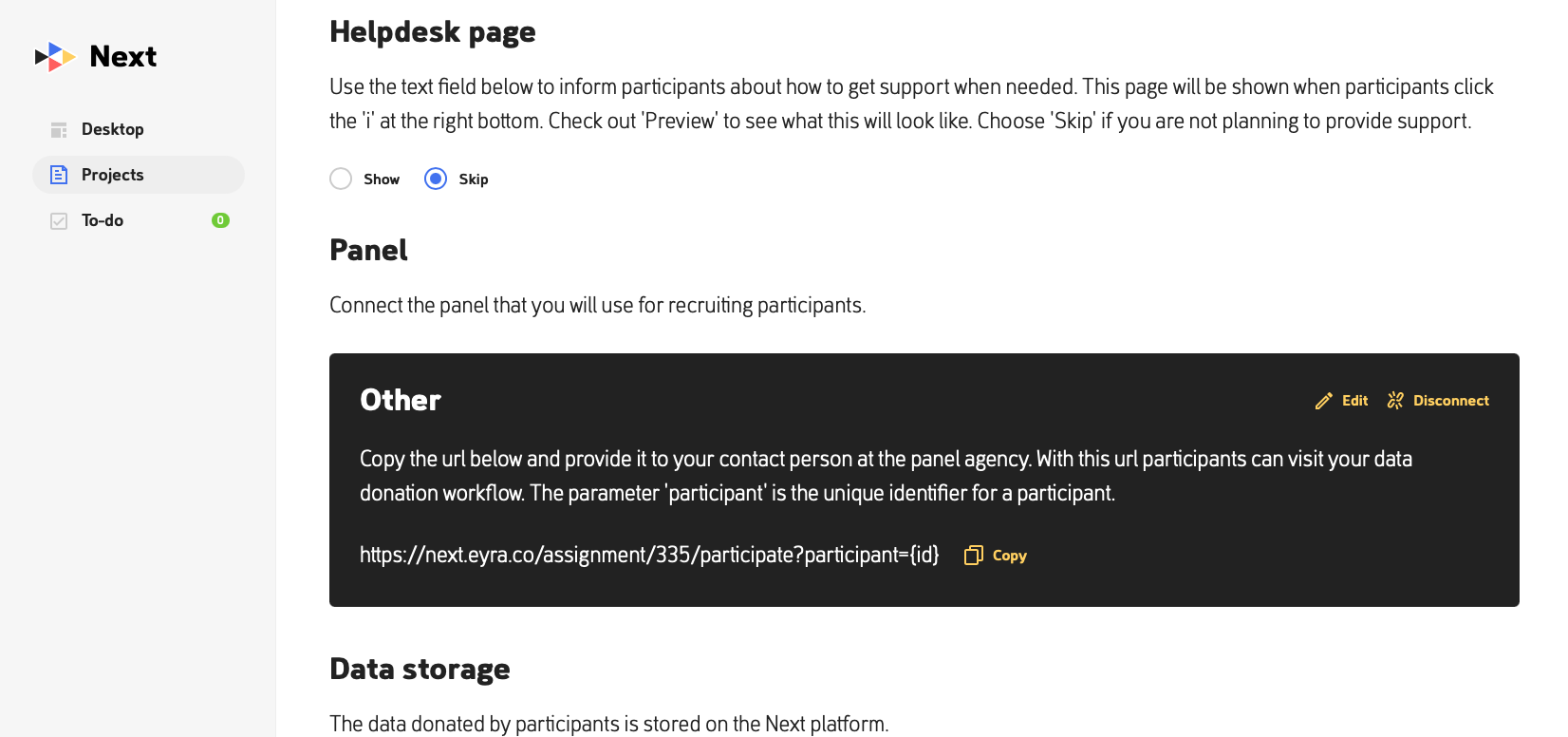
Figure. Next setup
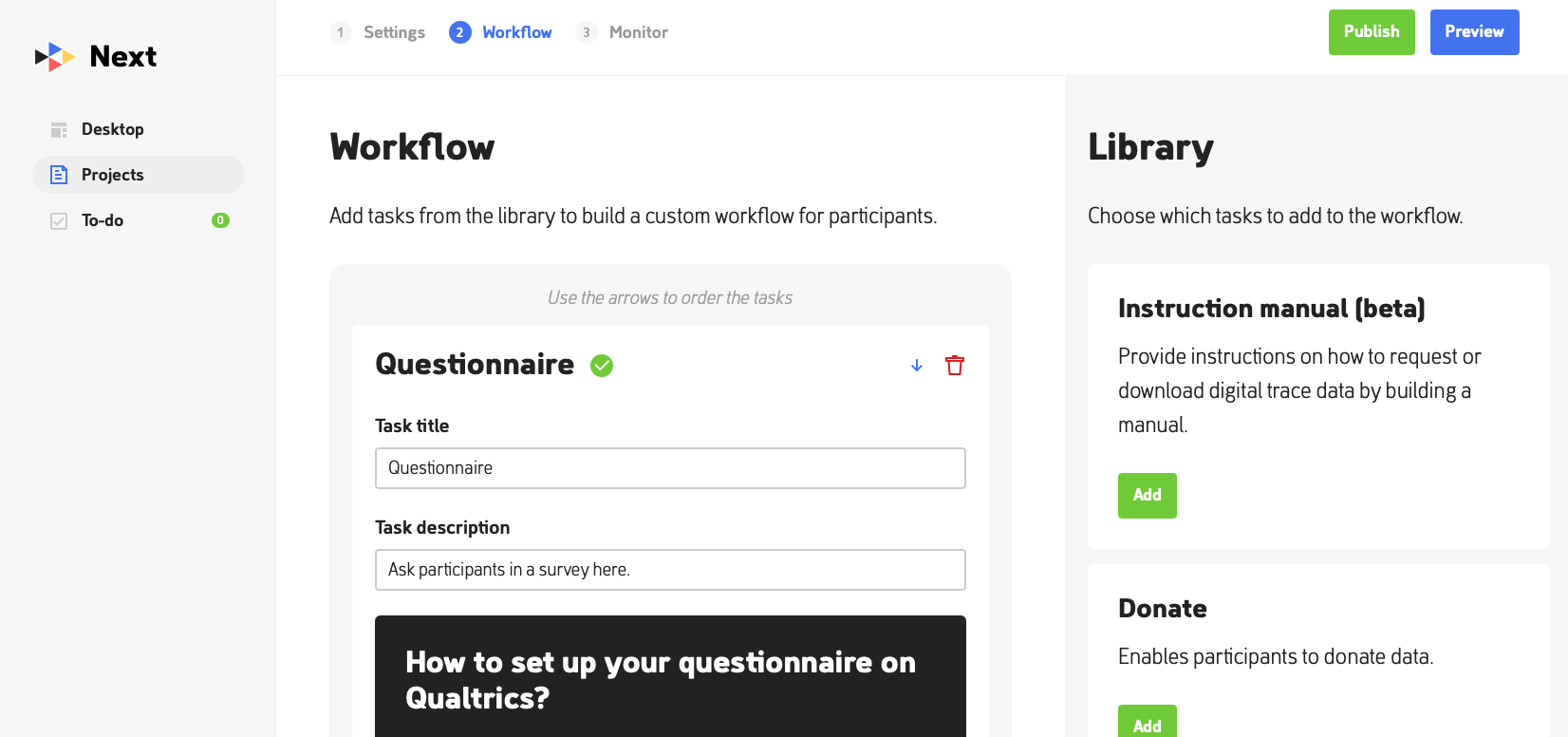
Figure. Next setup
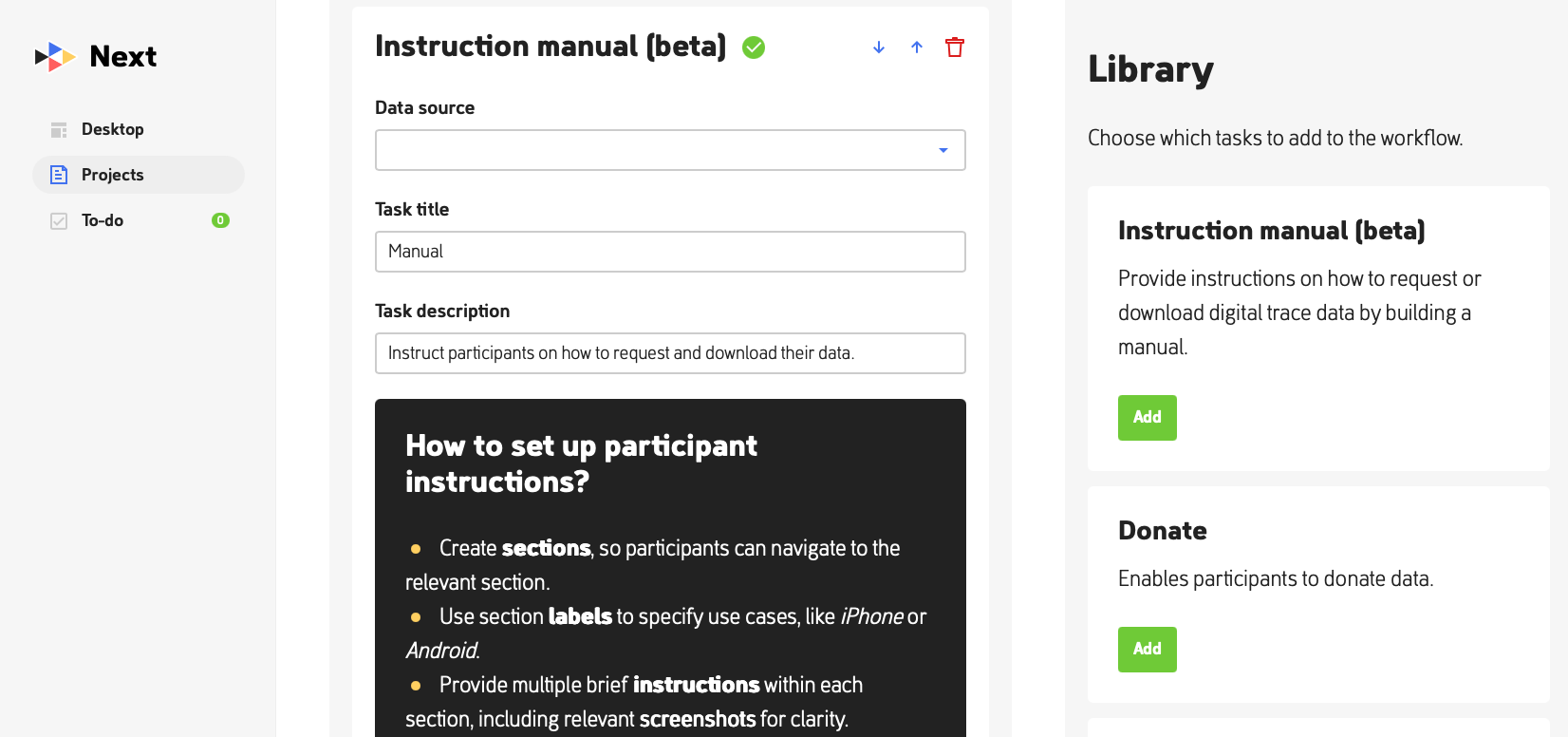
Figure. Next setup
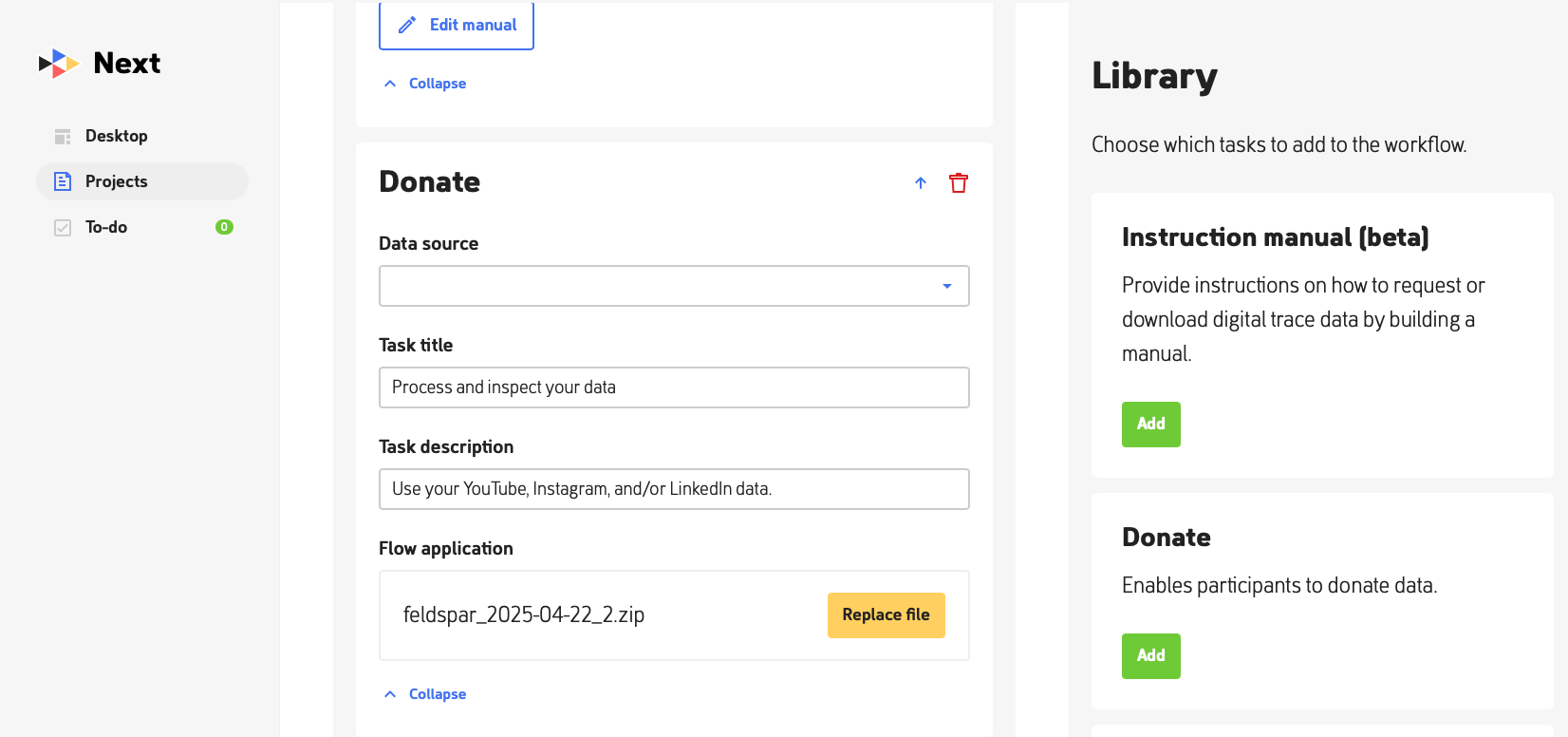
Figure. Next setup
Step I: Research design & tool set-up
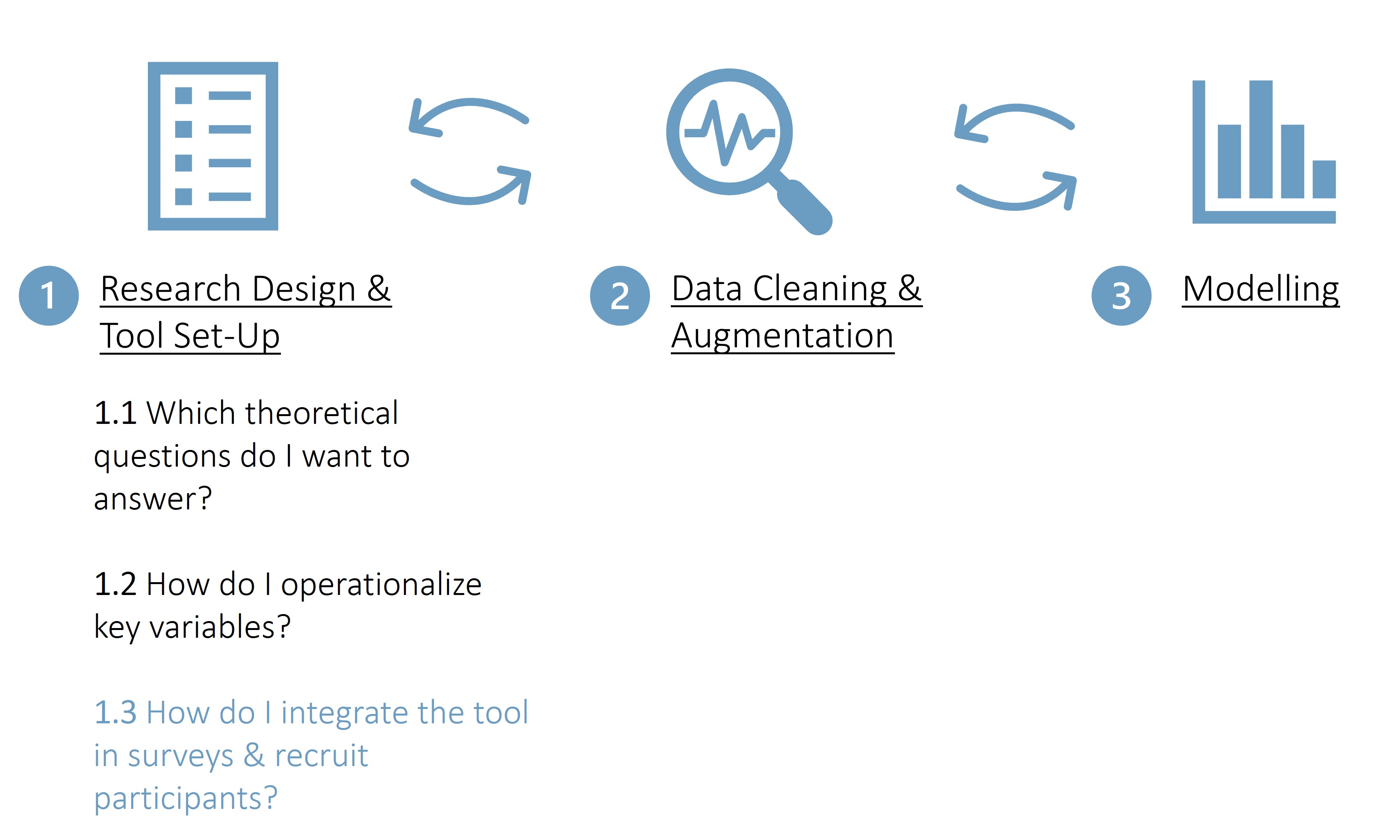
Step I.III: How do I integrate the tool in surveys & recruit participants?
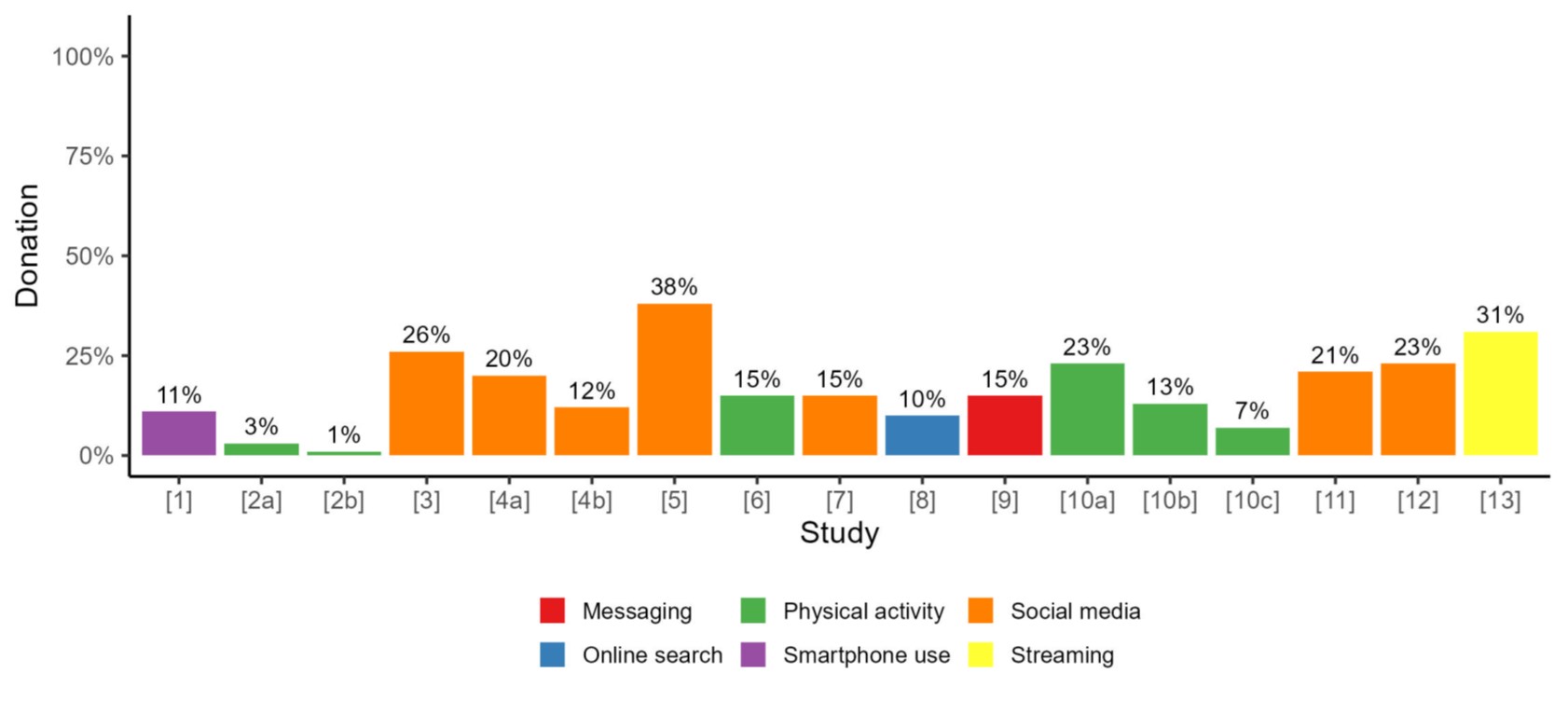
Low response rates (e.g., Hase & Haim, 2024; Keusch et al., 2024)
- Behavioral intentions as “willingness to donate” high (79-52% of survey respondents)
- Actual behavior as “participation in data donation” low (38-1% of survey respondents)
- Well known intention-behavior gap (Kmetty & Stefkovics, 2025)
Step I: Research design & tool set-up
Figure. Data donation study - researcher perspective
Step II: Data cleaning & augmentation
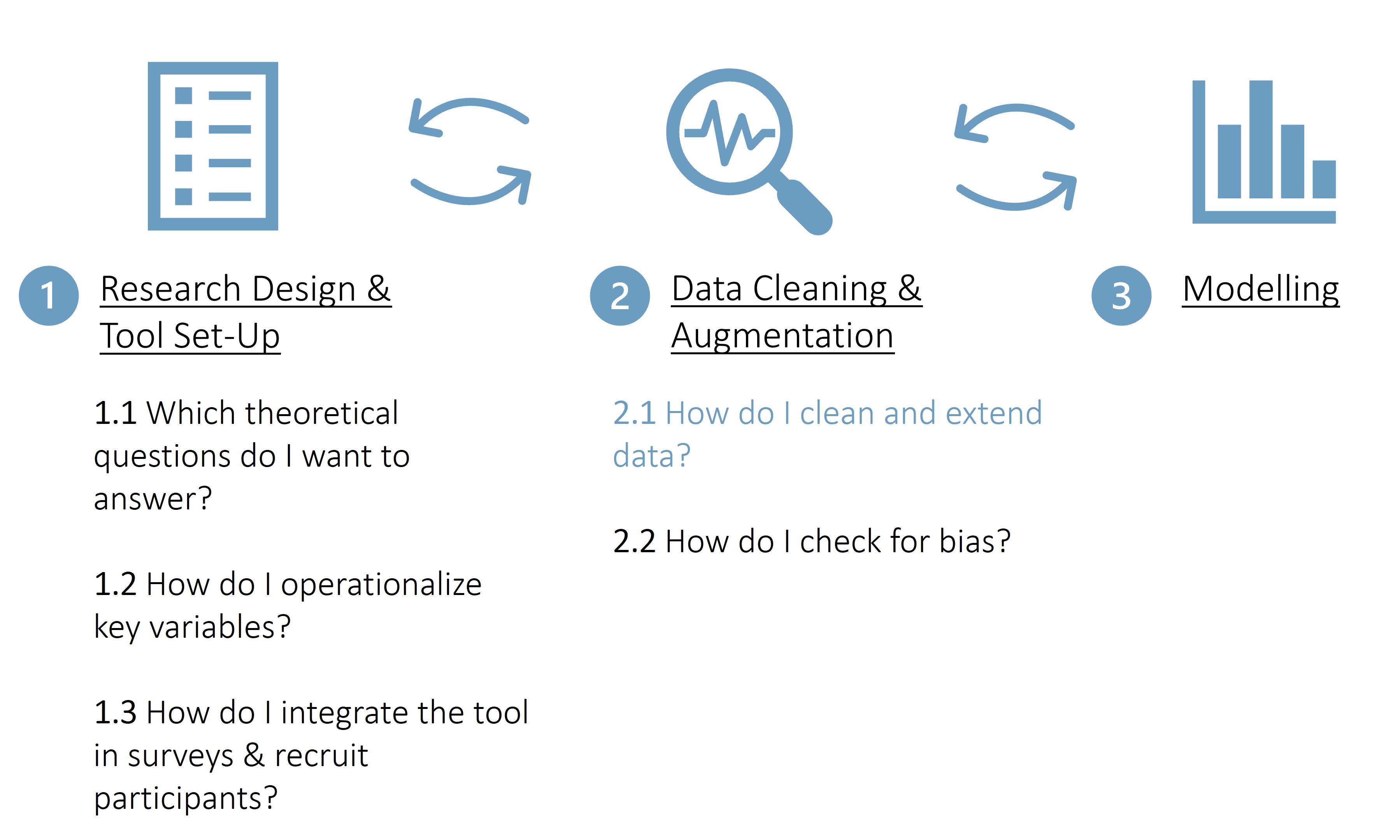
Figure. Data donation study - researcher perspective
Step II.I: How do I clean and extend data?
This is how your data may look like:
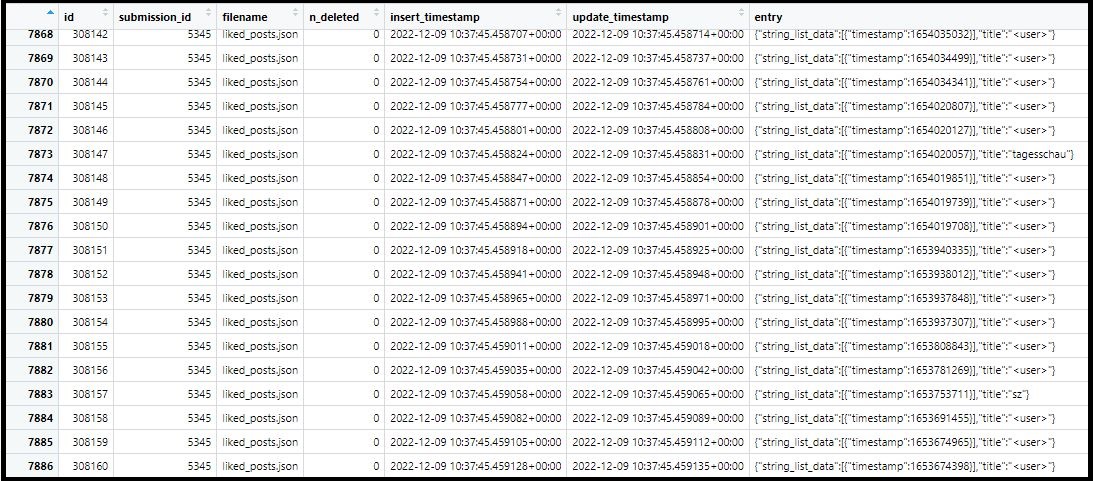
Figure. Donated data - example
Step II.I: How do I clean and extend data?
This is how your data may look like:

Figure. Donated data - example
📢 Task 4: Classify search terms
Download the “Data for Task 4” from the website. It contains YouTube searches from a German social media sample. Either discuss this conceptually or try this in R/Python…..
How you would clean the data?
How you would identify health-related searches using manual or automated coding?
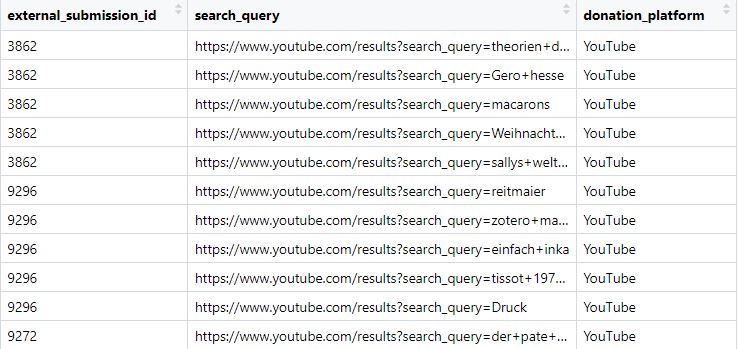
Figure. Donated data - example
Step II: Data cleaning & augmentation
Figure. Data donation study - researcher perspective
Step II: Data cleaning & augmentation
Figure. Data donation study - researcher perspective
Step III: Modelling
Figure. Data donation study - researcher perspective
📢 Task 5: Example Analysis of YouTube Watch history
Download the “Data for Task 5” from the website or use your own YouTube watch history. Also, load the respective R-code. Run the code (you just have to change the location and name of your data):
On which day do you mostly watch YouTube?
At what time do you mostly watch YouTube?
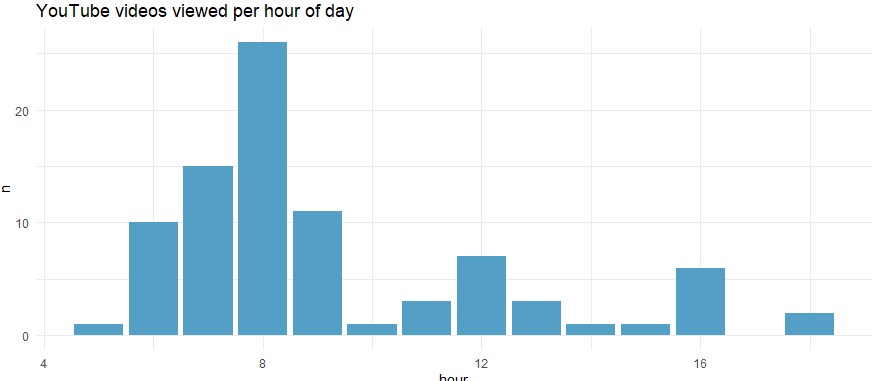
The idea for this code and analysis was provided by Michael Scharkow, University of Mainz.